AI, cyber security, Education, encryption
Every few years, education technology hands schools a new object to panic about. In 2023 it was the chatbot. Districts drafted emergency bans over a weekend, then quietly reversed them a semester later when it became clear the technology wasn’t going anywhere and the bans were unenforceable anyway. The whole episode was instructive—not because of what it said about AI, but because of what it revealed about how schools respond to structural change. They reach for a policy when what they need is an architecture.
That is the central problem this piece is meant to solve. The question facing K-12 leadership is no longer “should we allow ChatGPT?” That framing is already obsolete. The real question is whether an institution has the governance, capacity, and pedagogical design to absorb a general-purpose technology without either recklessly deploying it or reflexively rejecting it. Both extremes are failures of leadership. A ban outsources judgment to fear; uncritical adoption outsources judgment to vendors. Neither is a plan.
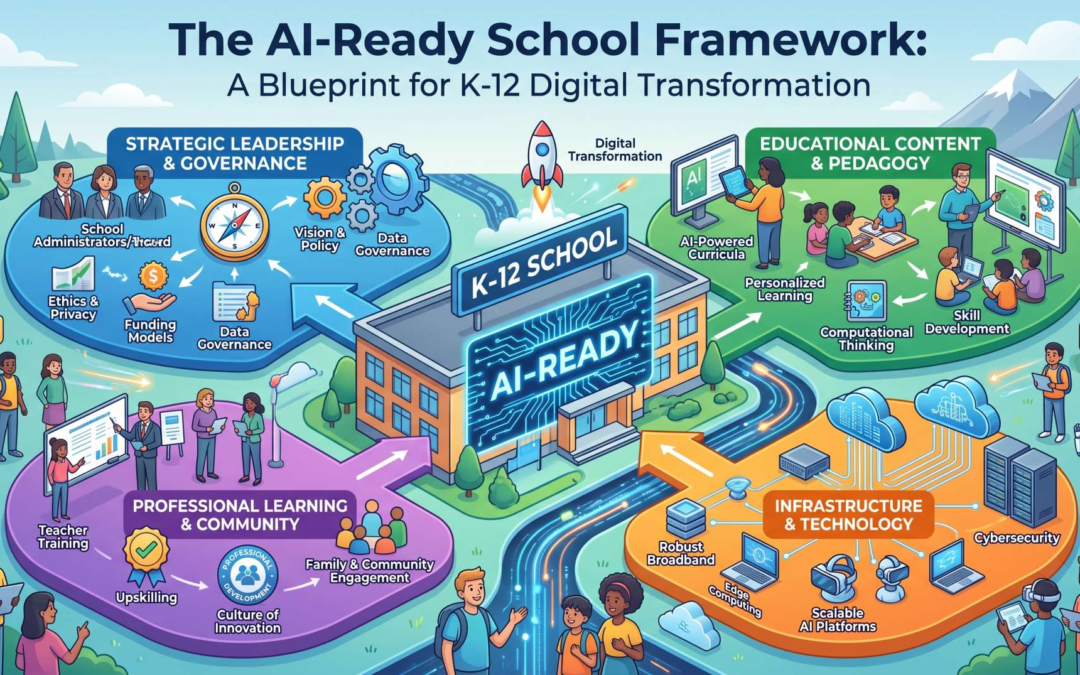
What follows is a framework—four load-bearing domains, sequenced deliberately, plus a maturity ladder that lets a district honestly assess where it stands. It is not a product recommendation and it is not a manifesto about the future of learning. It is a blueprint for the far less glamorous work of making a school system institutionally ready for tools it does not yet fully understand.
The False Binary at the Center of the Conversation
Start by naming the trap. The public discourse around AI in schools has organized itself around a single axis: enthusiasm versus prohibition. Vendors and conference keynotes occupy one end, promising personalized learning and teacher liberation. Anxious op-eds and hastily written acceptable-use policies occupy the other, warning about cheating and cognitive decline.
Both positions share a hidden assumption—that the decision is fundamentally about the tool. It is not. The tool is the least interesting variable. Whether a given AI model is impressive this quarter matters far less than whether the district that adopts it has answered a prior set of questions: Where does student data go? Who is accountable when the system errs? What are teachers actually being asked to change about their practice? What is the point of the assignment now that a machine can complete it?
A school that has answered those questions can adopt almost any tool safely. A school that has not will be endangered by the best tool on the market. This is why the framework treats AI as infrastructure rather than as a classroom novelty—and why the domains below are ordered the way they are. You cannot build capacity on an ungoverned data foundation, and you cannot redesign curriculum for people you haven’t trained.
Domain One: Data and Governance — The Foundation
Nothing else in this framework functions without this layer, and it is precisely the layer that gets skipped, because it is the one no student ever sees.
K-12 institutions occupy a uniquely regulated position. FERPA governs the privacy of education records; COPPA governs the collection of data from children under thirteen; many states layer their own student-privacy statutes on top. Consumer AI tools were, for the most part, not built with these constraints in mind. When a teacher pastes a struggling student’s essay into a general-purpose chatbot to generate feedback, that teacher may have just transmitted personally identifiable information about a minor to a third-party system with an opaque data-retention policy. No malice, no policy violation the teacher was aware of—just a governance vacuum doing what vacuums do.
The remedy is not a ban on tools. It is a governance stack that most districts already know how to build for other systems and simply haven’t extended to AI:
A vetted-tools list, maintained by a named person or committee, distinguishing enterprise or education-tier products with contractual data protections from consumer products that must never touch student data. The distinction is legally and practically enormous, and most staff have no idea it exists.
Data-flow clarity for every approved tool—a plain-language answer to “what does this system collect, where does it store it, how long does it keep it, and does it train on our inputs?” If the vendor cannot answer, that is the answer.
Procurement discipline that treats AI features as data-processing agreements, not as bullet points on a feature sheet. The moment a familiar LMS or assessment platform adds an AI layer, its data posture may have quietly changed. Renewal is the moment to re-vet, not rubber-stamp.
An incident pathway so that when something does go wrong—and it will—there is a route other than silence or improvisation.
This domain is unglamorous, and that is exactly why it is the test of serious leadership. A district that starts its “AI strategy” with a teacher-training day and skips governance has built a house starting with the curtains.
Domain Two: Educator Capacity — The Co-Pilot Problem
Once the foundation is sound, the work moves to people. And here the framework insists on a distinction that most professional development quietly elides: the difference between AI as a co-pilot and AI as a crutch.
A co-pilot extends a teacher’s judgment. It drafts a first-pass rubric the teacher then revises against what she knows about her class. It generates three versions of a word problem so she can differentiate without spending her prep period retyping. It surfaces a pattern in formative-assessment data that she interprets. In every case, professional expertise remains in command, and the tool absorbs the low-value labor that has been quietly eroding teacher time for years.
A crutch inverts that relationship. The tool generates the feedback and the teacher forwards it unread. The tool writes the lesson plan and the teacher delivers content she doesn’t fully understand. The tool grades the essays and no human ever reads the student’s actual thinking. The output may look identical to co-pilot use. The professional judgment underneath has quietly evacuated.
The uncomfortable truth is that most AI professional development fails precisely because it teaches the crutch while claiming to teach the co-pilot. It demonstrates impressive outputs, hands teachers a list of prompts, and calls it upskilling. It trains compliance, not judgment. Teachers leave able to operate the tool and no better equipped to decide when not to.
Capacity-building that works looks different. It is grounded in the teacher’s existing pedagogical expertise rather than treating AI as a replacement for it. It spends as much time on the failure modes—hallucinated facts, confident wrongness, subtle bias in generated examples, the way convenient defaults flatten instruction toward the generic—as on the capabilities. It is ongoing and job-embedded rather than a single inspirational session. And critically, it protects the teacher’s authority to override the machine, which means school culture has to reward that override rather than quietly punishing the teacher who is slower because she actually read the essays.
The goal is not teachers who use AI. The goal is teachers whose judgment is amplified by AI and never displaced by it. Those are not the same outcome, and no framework worth the name should pretend they are.
Domain Three: Curriculum and Assessment — The Redesign
This is where the technology stops being an operational question and becomes a pedagogical one. If a machine can produce a competent five-paragraph essay in four seconds, the five-paragraph essay is no longer measuring what teachers thought it measured. The instinct is to build detection tools and catch the cheaters. That is a losing arms race, and it misdiagnoses the problem. The assessment was already fragile; AI merely exposed the fragility.
The productive response is to ask what the assignment was actually for. If the essay existed to develop and demonstrate a student’s reasoning, then the assessment needs to make reasoning visible in ways a one-shot output cannot fake—drafts, revisions, oral defenses, in-class writing, annotation of one’s own choices, the messy documented process rather than the polished artifact. Process becomes the evidence. This is not a workaround forced on schools by AI; it is a return to something assessment arguably should have been doing all along.
Curriculum redesign runs alongside. Some skills genuinely diminish in value when a machine performs them competently. Others rise sharply: the ability to evaluate whether an AI output is correct, to detect where it is subtly wrong, to know what question to ask in the first place, to synthesize across sources a machine has merely summarized. These are not futuristic “21st-century skills” abstractions—they are concrete, teachable competencies, and they are increasingly the point of a K-12 education rather than an accessory to it.
The discipline this domain demands is resisting two temptations at once: bolting an “AI unit” onto the existing curriculum as a token gesture, and throwing out foundational knowledge on the theory that the machine now holds it. A student who cannot reason cannot supervise a machine that reasons badly. Foundational knowledge is not made obsolete by AI; it becomes the prerequisite for using AI responsibly.
Domain Four: Student Agency and Digital Citizenship — The Point
The three domains above serve this one. The purpose of a governed, capable, redesigned school is not efficiency. It is the formation of young people who can live and think alongside these systems without being diminished or deceived by them.
That means teaching students, at developmentally appropriate levels, what these tools are and are not: that a fluent answer is not a true one, that a confident tone is not evidence, that the system reflects the data and incentives of the people who built it. It means treating disclosure and honesty about AI use as a literacy to be taught rather than a crime to be caught—a distinction that changes the entire relationship between teacher and student. And it means attending to the quieter risks that governance frameworks tend to miss: the erosion of productive struggle when help is always one prompt away, and the emotional and developmental questions raised when students form habitual relationships with responsive, always-available systems.
A school can nail governance, train its teachers, and redesign its assessments, and still fail here if it produces students who are efficient users of AI and passive before it. Digital citizenship is not the soft add-on at the end of the framework. It is the outcome the rest of the framework exists to make possible.
A Maturity Ladder, Not a Finish Line
Because these domains are uneven work, districts need an honest way to locate themselves rather than a binary “AI-ready or not.” Four stages are useful:
Reactive — The district responds to AI incident by incident, through bans, panics, and one-off memos. No coherent data governance for AI. This is where most systems have been.
Managed — Governance exists: a vetted-tools list, procurement discipline, a data-flow policy. Teachers have basic guidance. AI is contained and safe, if not yet pedagogically integrated.
Integrated — Educator capacity is genuine and ongoing, assessment redesign is underway, and AI use is deliberate rather than defensive. The tool serves stated pedagogical goals.
Adaptive — Student agency and citizenship are woven through the curriculum, the district evaluates its own AI use for equity and effect, and it can absorb new tools without starting from zero each time.
The point of the ladder is candor. A district running flashy AI pilots while sitting at Reactive on governance is not innovating; it is exposed. Maturity is sequential for a reason.
The Work Nobody Applauds
The seductive version of AI in education is the demo: the personalized tutor, the instant feedback, the liberated teacher. The real version is a procurement review, a data-flow audit, a professional-development series that spends its afternoon on hallucination and bias, a department meeting about what an essay is now for. None of it makes a good keynote. All of it is what actually protects students and empowers teachers.
That is the strategist’s wager embedded in this framework: that the districts which thrive amid AI will not be the ones that adopted the flashiest tools fastest, but the ones that built the boring infrastructure first—governance before capacity, capacity before redesign, and all of it in service of students who can think for themselves in a world of machines that will happily think for them. The blueprint is not complicated. It is only demanding. And in a domain crowded with hype, demanding and boring may be the most forward-thinking posture a school can take.

AI, cyber security, Education, encryption, honest
A practical guide for parents and educators navigating the gap between screen time anxiety and digital fluency
There is a particular kind of parental guilt that has emerged in the last decade, one that didn’t exist for previous generations: the guilt of not knowing whether the tablet in your child’s hands is a Trojan horse or a training ground. Educators feel a version of this too, standing in front of a classroom of eight-year-olds who can navigate a touchscreen before they can tie their shoes, unsure whether the right move is to lean in or pull back.
The dominant conversation about children and technology has been organized almost entirely around restriction: screen time limits, app blockers, age gates, “wait until eighth grade” pledges. These are not unreasonable responses. But they answer only half the question. The half they skip is this: if not passive consumption, then what? What does healthy, developmentally appropriate technology use actually look like for a five-year-old, or a ten-year-old, when it’s not just “less of it”?
This piece is an attempt to answer that half. Not a screen-time rulebook, but a framework for the affirmative case — what to build toward, not just what to avoid.
The Core Shift: From Consumption to Creation
The most useful distinction in this entire conversation isn’t “screens vs. no screens.” It’s consumption vs. creation.
A child watching an algorithmically-selected video feed and a child using a simple block-based coding tool to build a game are both “on a screen.” But almost nothing else about those experiences is the same. One is a closed loop designed to hold attention. The other is an open loop that asks the child to direct it.
This distinction matters because it gives parents and educators something more actionable than a stopwatch. Instead of asking “how many minutes,” the better question becomes “what is this time producing.” A useful mental model:
Passive digital time: media consumption, algorithmic feeds, most gaming that involves no construction or authorship
Active digital time: coding, digital art creation, structured AI exploration with a defined task, building something that didn’t exist before the session started
Neither category needs to disappear from a child’s life. But the ratio matters enormously, and most household defaults skew heavily toward the passive category simply because it requires less setup, less adult involvement, and less tolerance for a child’s frustration when something doesn’t work on the first try.
Shifting that ratio doesn’t require expensive tools or a parent who codes. It requires treating “making something” as a legitimate and even preferable use of device time, and being willing to sit through the boring, glitchy, unglamorous parts of a young child learning to build.
What Age-Appropriate Actually Means (Not “Simplified,” But “Scaffolded”)
A common mistake in introducing technology to young learners is conflating “age-appropriate” with “watered down.” A five-year-old doesn’t need a dumbed-down version of coding; they need a version scaffolded to their actual cognitive stage.
For children roughly 5–7, the entry point is best kept tactile and sequential: simple drag-and-drop coding environments where cause and effect are immediate and visual, physical robotics kits that respond to basic instructions, and AI interactions that are tightly structured — asking a voice assistant to help sort information into categories, for instance, rather than open-ended conversation.
For children roughly 8–10, introducing basic block-based programming with actual logic (loops, conditionals) becomes appropriate, alongside guided, co-piloted AI exploration where the adult sets the task and reviews the output together. This is also the age where the first real conversations about “what AI is and isn’t” can land — that it predicts patterns rather than “thinks,” that it can be wrong, that it doesn’t know things the way a person knows things.
For children roughly 11–12, more independent exploration becomes reasonable: text-based coding introductions, using AI tools for specific, bounded creative or research tasks with adult check-ins rather than adult presence, and direct instruction on things like how training data shapes AI output, why the same question can get different answers, and how to verify what a tool tells them.
The throughline across all three bands is that autonomy is earned in increments, not granted all at once. A ten-year-old who has spent two years building things with adult scaffolding is genuinely ready for more independence. A ten-year-old handed an unfiltered AI chatbot with no prior scaffolding is not being given autonomy — they’re being given exposure.
Safe AI Exploration Is a Skill, Not a Setting
Parental controls and content filters have a role, but treating them as the whole solution creates a false sense of security. Filters manage exposure; they don’t build judgment. And judgment is the thing children actually need, because the tools they’ll encounter — at school, at a friend’s house, five years from now in forms nobody has built yet — will not always come with a filter attached.
A more durable approach treats AI literacy the way we’ve historically treated media literacy: as a set of questions a child learns to ask automatically, rather than a wall that keeps certain content out.
Three habits are worth building early and repeating often:
“Where did this come from?” — a basic reflex of asking whether an AI answer, an image, or a piece of information has a source, and what happens when you ask the tool directly where it got something.
“Could this be wrong?” — the understanding that confident-sounding output isn’t the same as correct output, ideally demonstrated concretely by finding an AI mistake together rather than just stating it as a rule.
“Whose job is the final decision?” — a clear, repeated message that AI tools can draft, suggest, and generate, but a human — the child, or the trusted adult — makes the actual call on what’s true, what’s appropriate, and what gets used.
These habits transfer. A child who has practiced them with a homework helper tool is far better positioned to apply them later to a search engine, a social feed, or a stranger’s claim online than a child who has only ever been told “don’t use AI without asking.”
Embedding Social-Emotional Learning Into Digital Interaction
The SEL dimension of this conversation tends to get treated as separate from the technical skills conversation — as if empathy and coding belong in different units. In practice, some of the richest SEL moments available to educators and parents right now are happening inside digital interactions themselves, if adults are looking for them.
A few concrete entry points:
Frustration tolerance through debugging. When a child’s code doesn’t work, or their digital art project glitches, the instinct — both the child’s and the supervising adult’s — is often to fix it immediately. Resisting that instinct and instead narrating the problem-solving process (“okay, it’s not doing what we expected, what do you think happened?”) turns a technical hiccup into a genuine emotional regulation exercise. This is arguably more valuable long-term than the coding skill itself.
Perspective-taking through AI’s limitations. When an AI tool gives an answer that’s clearly wrong or oddly phrased, it’s a natural opening to talk about how the tool “sees” the world differently than a person does — no memory of yesterday’s conversation, no ability to read a room, no gut feelings. Children are often quick to notice this once it’s pointed out, and it builds a useful intuition for the difference between artificial and human understanding.
Boundary-setting as a taught skill, not just an enforced rule. Rather than presenting screen limits purely as parental decree, involving children in naming why a boundary exists — “we’re stopping now because your brain needs a break to process what you learned” — builds the internal skill of self-regulation, which matters more once a child is old enough that external enforcement becomes impractical anyway.
None of this requires a curriculum. It requires treating the moments that already happen — the glitch, the wrong answer, the end of screen time — as material rather than obstacles.
A Simple Weekly Structure Educators and Parents Can Actually Sustain
Frameworks that require significant new infrastructure tend to collapse under the weight of everyday life. What tends to hold up is something closer to a loose weekly rhythm than a rigid program:
One session of guided creation — a coding activity, a digital art project, a structured AI-assisted task — with adult involvement, even if that involvement is just being in the room and asking questions.
One deliberate conversation, five or ten minutes, about something the child encountered digitally that week: something an AI got wrong, something confusing they saw, a boundary that felt hard to follow. The goal isn’t a lecture; it’s making digital reflection a normal, expected weekly habit rather than something that only happens after a problem.
Ongoing, unscheduled passive time, because eliminating it entirely is neither realistic nor necessary — the goal is rebalancing the ratio, not achieving purity.
This is deliberately modest. The families and classrooms that sustain healthy digital habits over years, rather than for a few motivated weeks, are usually the ones running something this simple and repeatable, not something elaborate and short-lived.
The Actual Goal
Digital citizenship for young learners isn’t a destination — a certificate of internet safety a child earns and then possesses. It’s closer to a muscle, built through repeated small exercises: making instead of just watching, asking where something came from, noticing when a tool gets something wrong, naming why a boundary exists.
The technology itself will keep changing. The specific tools a ten-year-old uses today will look primitive in five years, the way today’s tools would have looked like science fiction fifteen years ago. What won’t change is that a child who has practiced creation, questioning, and self-regulation with whatever tool is in front of them will adapt to the next one. A child who has only ever practiced compliance with a filter will need the filter forever.
That’s the actual balancing act: not screen time versus no screen time, but building the judgment that makes the specific rules eventually unnecessary.

AI, cyber security, Education, encryption, GCC
WHO TRAINS THE AI GRADER? AUDITING THE HIDDEN RUBRICS INSIDE AUTOMATED ASSESSMENT TOOLS
Automated grading tools are marketed on consistency and speed, and on both counts they often deliver. What they rarely deliver is transparency about what they’re actually rewarding, and that gap is becoming a real institutional liability as these tools move from grading multiple-choice quizzes into evaluating open-ended student writing and reasoning.
The Black Box of Automated Grading
Most institutions adopting AI grading tools know remarkably little about how the underlying model arrives at a score. Vendors describe their products in terms of outcomes, alignment with human grader scores, faster turnaround, reduced grading fatigue, but rarely disclose the actual rubric the model has learned to apply. That rubric isn’t written down anywhere a teacher can review it. It’s encoded implicitly in the patterns the model picked up during training, which means it can reward things no one ever intended it to reward.
What Rubrics Are Actually Encoded
Research on automated essay scoring has repeatedly found that these systems can latch onto superficial proxies, sentence length, vocabulary sophistication, even punctuation patterns, that correlate with quality in the training data without actually measuring the reasoning or argument quality teachers care about. A model trained on a set of human-graded essays will absorb whatever biases existed in that grading, including unconscious preferences for certain writing styles or familiar phrasing patterns that have nothing to do with the rigor of the underlying thinking. The institution adopting the tool inherits those biases without ever seeing them named.
The Case for Audits
This is not a new problem in principle. Algorithmic auditing is a mature practice in domains like lending and hiring, where the consequences of biased automated decisions are well understood and increasingly regulated. Education has been slower to apply the same scrutiny to assessment tools, partly because the stakes of a single grading decision feel smaller than a loan denial. But aggregated across an entire institution and an entire student population, a systematically biased grading rubric has the same kind of structural impact, just distributed more quietly.
Building an Audit Framework
Institutions don’t need to build sophisticated technical auditing capacity from scratch to start addressing this. A practical starting point is sample testing, periodically having human graders score a representative sample of the same student work the AI tool graded, and comparing not just the scores but the apparent reasoning behind discrepancies. Building a structured teacher review loop, where flagged or borderline AI scores get routed to a human grader before being finalized, catches the worst failures without abandoning the efficiency gains entirely. And procurement teams should be treating vendor transparency about training data and known failure modes as a contractual requirement, not a nice-to-have. A vendor unwilling to disclose what their model has been shown to over-reward or under-reward is asking institutions to adopt a rubric they’re not allowed to see.

